Synthetic Song Detection
A novel deep learning system for detecting end-to-end AI-generated music, featuring a new benchmark dataset and a highly efficient transformer model.
The Challenge: Detecting a New Wave of AI Music
The recent surge in end-to-end generative models like Suno and Udio has created a new challenge: detecting AI-generated songs where every component—vocals, music, and lyrics—is synthetic. Existing “deepfake audio” detectors were designed for simpler tasks and were inadequate for these complex, long-form audio files, creating a critical gap in audio forensics.
Our Solution: A New Dataset and an Efficient Model

We introduced two key innovations:
-
SONICS Dataset: A massive new benchmark dataset with over 97,000 songs, specifically designed for the end-to-end synthetic song detection task.
-
SpecTTTra Model: A novel and computationally efficient transformer architecture that excels at capturing the long-range temporal patterns in music, outperforming standard models like ViT by 8% while being 38% faster.
My Contributions
As a Co-First Author on this paper accepted to ICLR 2025, my contributions spanned the entire project pipeline. I was involved from the initial problem formulation and dataset strategy, through model experimentation and validation, to the final evaluation and deployment of our public demos on Hugging Face.
To be specific, I took ownership of several critical components that were foundational to the project’s success:

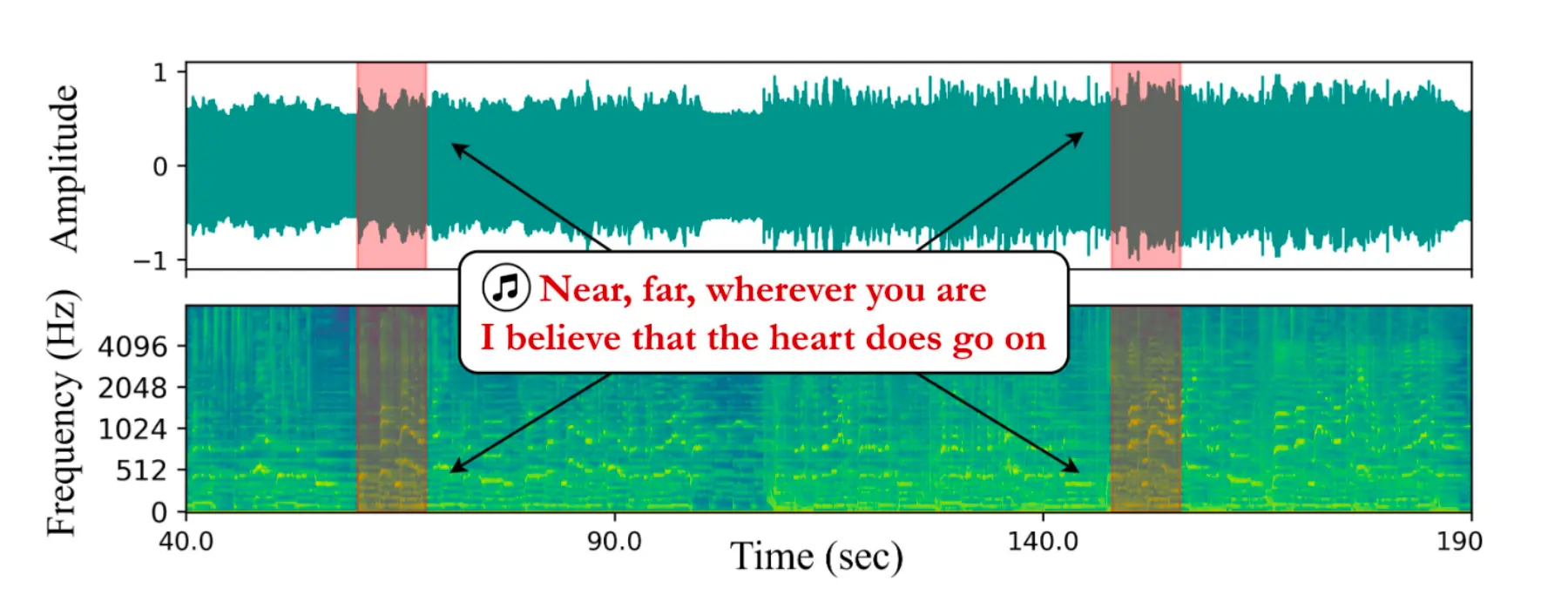
- Conducted the foundational gap analysis that established the need for a novel, computationally efficient model like SpecTTTra. My research proved that existing approaches were inadequate for long-form audio, directly motivating our system’s core design.
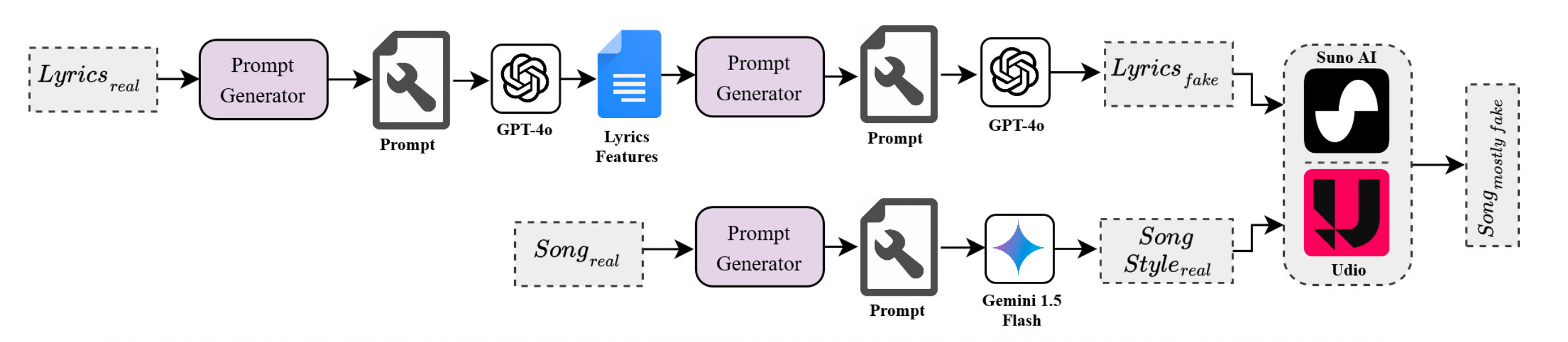
- Architected the style-extraction component of the ‘Mostly Fake’ generation pipeline, a key innovation that enabled our model to be trained on high-quality, stylistically diverse data.
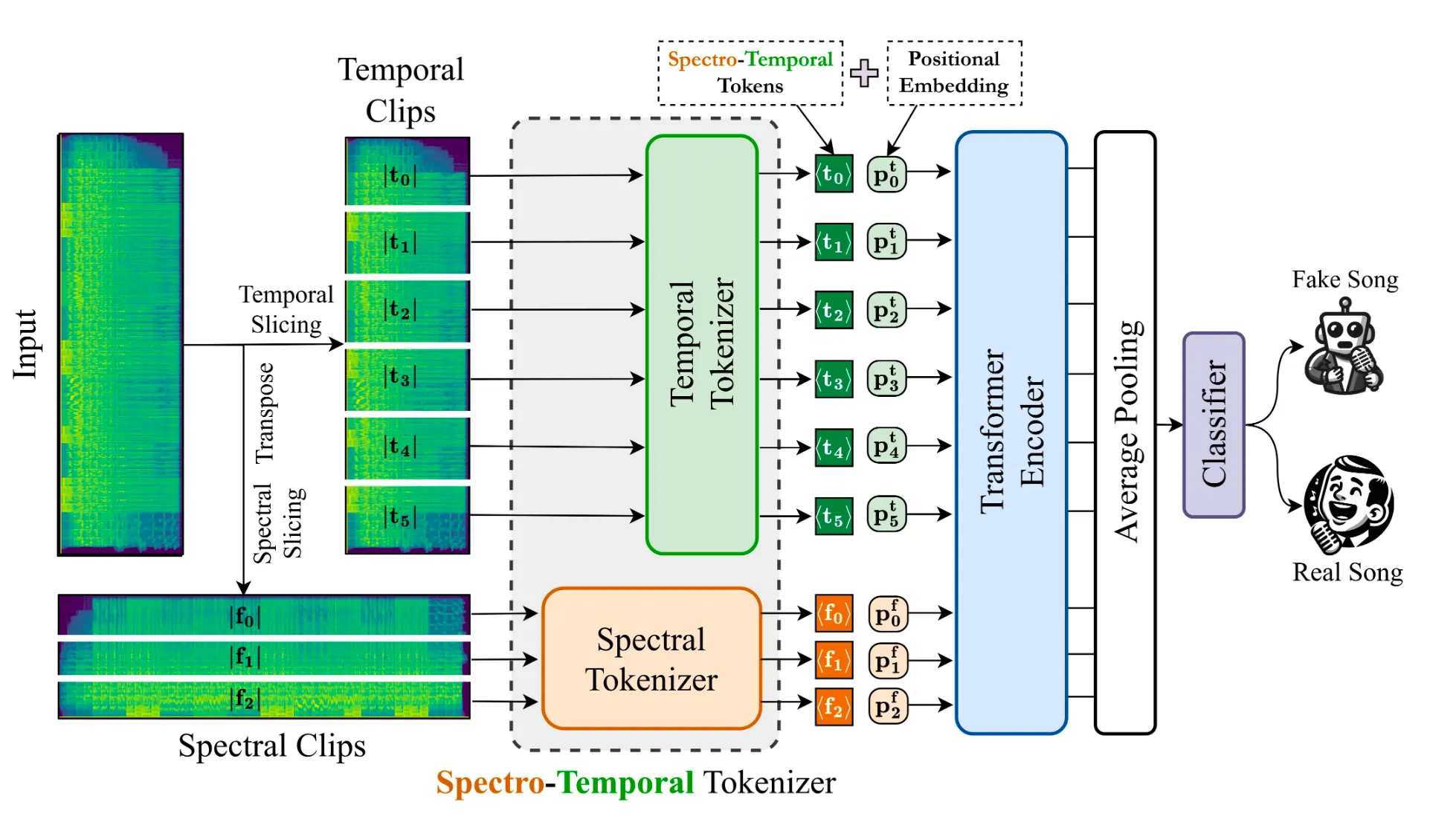
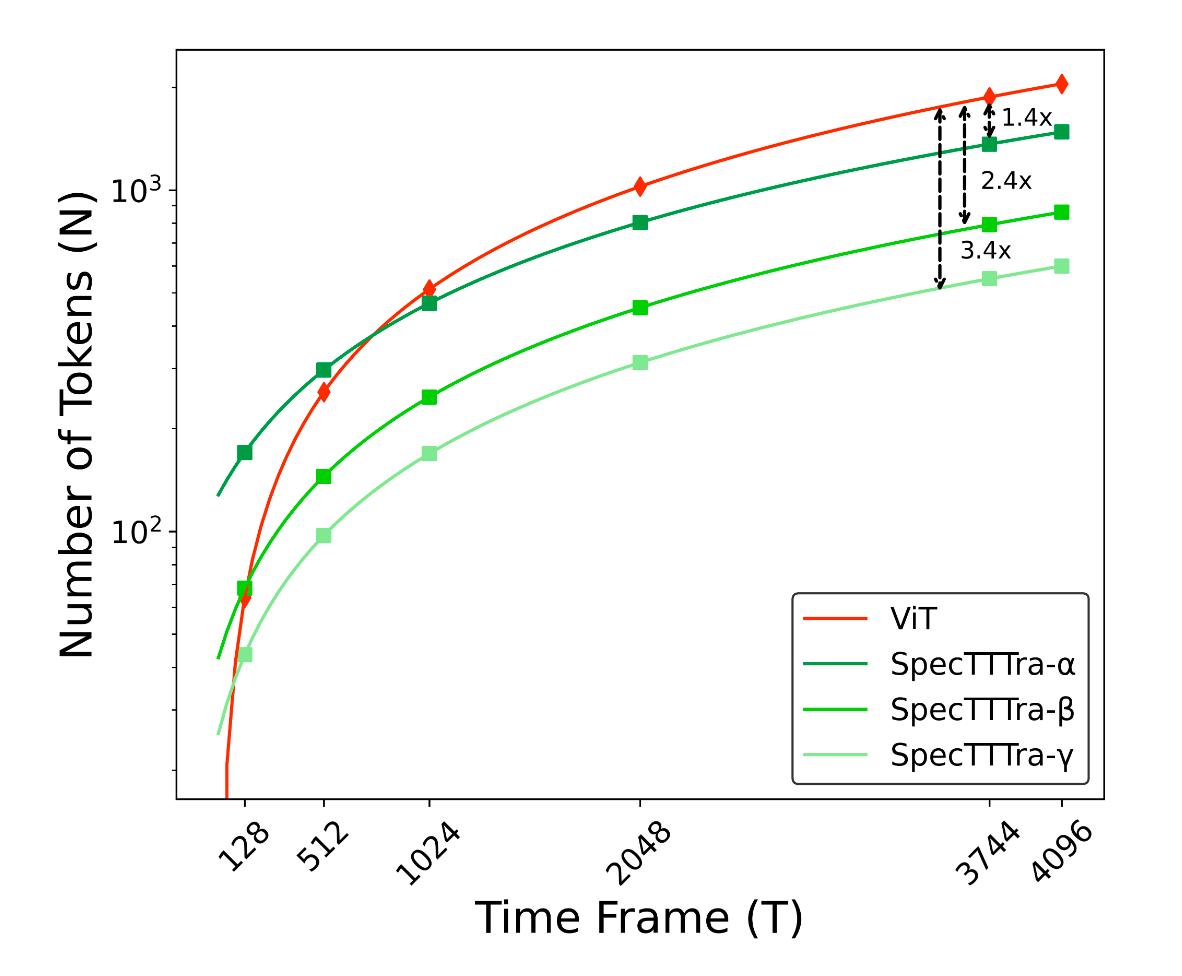
- Contributed to the model development lifecycle by conducting experiments on
SpecTTTravariants, analyzing performance trade-offs and tracking results to validate our architectural choices.
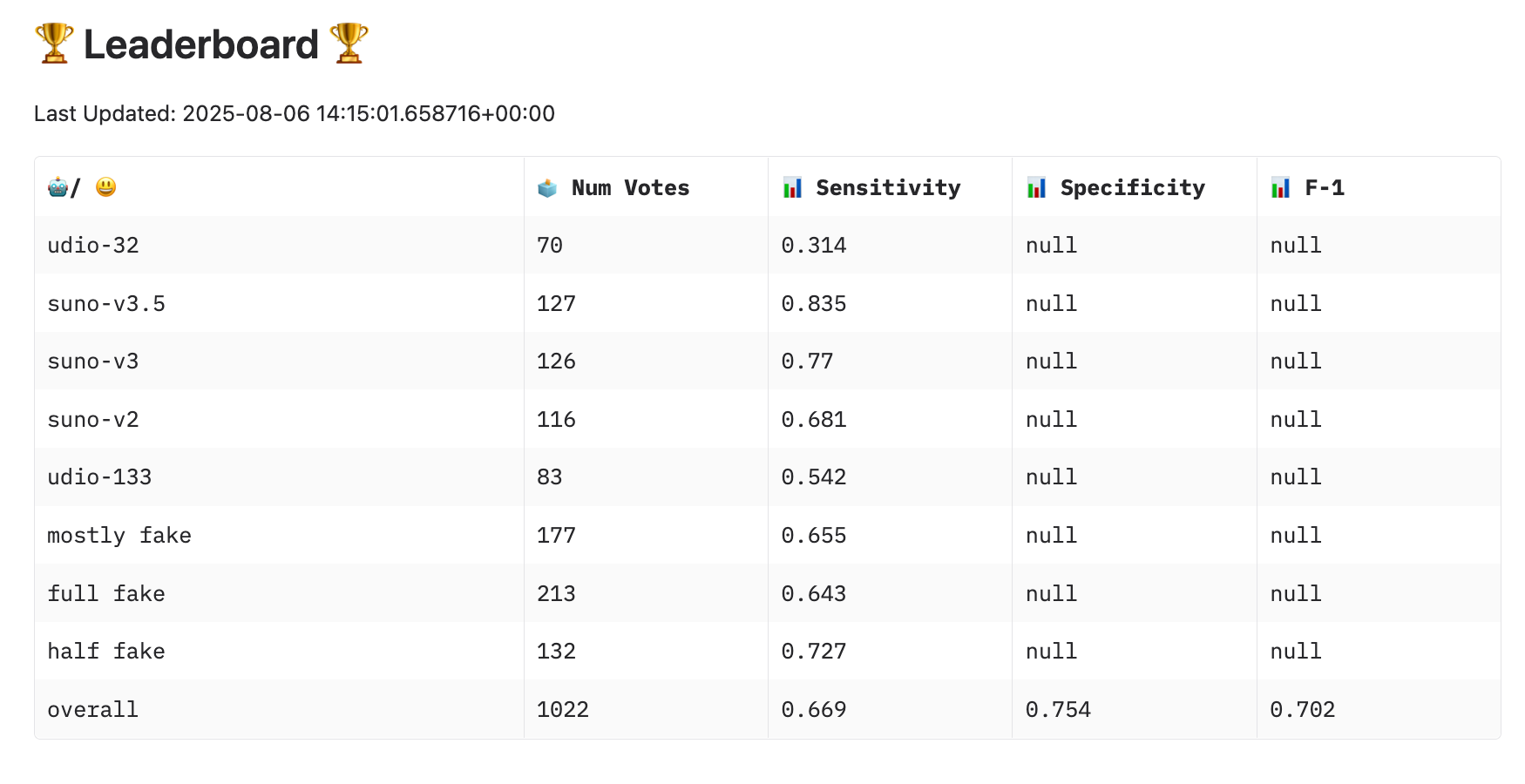
- Led the project’s human evaluation by creating the “Song Arena” on Hugging Face, a live system for crowdsourcing perceptual judgments and providing the ultimate real-world validation of our model’s success.
By contributing at every stage, I helped ensure our team not only built a state-of-the-art model but also delivered a robust, publicly-validated system that makes a meaningful contribution to the field of audio forensics.
For more details, please refer to the official project resources:
| Official Project Website | ArXiv Paper | Song Arena |