Publications
2025
-
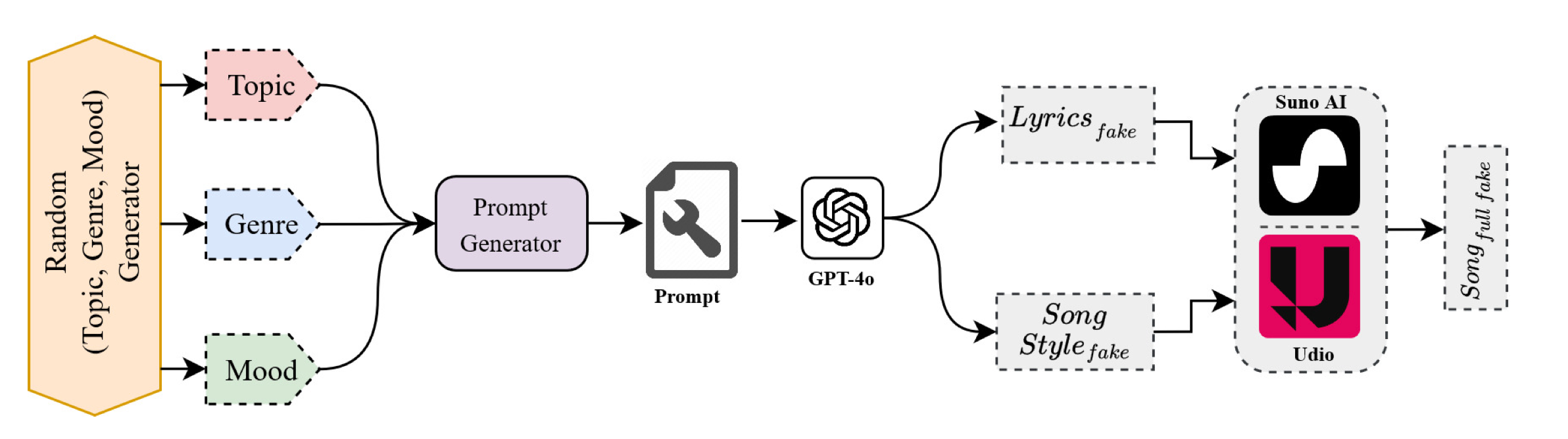 SONICS: Synthetic Or Not–Identifying Counterfeit SongsMd Awsafur Rahman*, Zaber Ibn Abdul Hakim*, Najibul Haque Sarker*, Bishmoy Paul*, and Shaikh Anowarul FattahInternational Conference on Learning Representations (ICLR), 2025
SONICS: Synthetic Or Not–Identifying Counterfeit SongsMd Awsafur Rahman*, Zaber Ibn Abdul Hakim*, Najibul Haque Sarker*, Bishmoy Paul*, and Shaikh Anowarul FattahInternational Conference on Learning Representations (ICLR), 2025The recent surge in AI-generated songs presents exciting possibilities and challenges. While these inventions democratize music creation, they also necessitate the ability to distinguish between human-composed and synthetic songs to safeguard artistic integrity and protect human musical artistry. Existing research and datasets in fake song detection only focus on singing voice deepfake detection (SVDD), where the vocals are AI-generated but the instrumental music is sourced from real songs. However, these approaches are inadequate for detecting contemporary end-to-end artificial songs where all components (vocals, music, lyrics, and style) could be AI-generated. Additionally, existing datasets lack music-lyrics diversity, long-duration songs, and open-access fake songs. To address these gaps, we introduce SONICS, a novel dataset for end-to-end Synthetic Song Detection (SSD), comprising over 97k songs (4,751 hours) with over 49k synthetic songs from popular platforms like Suno and Udio. Furthermore, we highlight the importance of modeling long-range temporal dependencies in songs for effective authenticity detection, an aspect entirely overlooked in existing methods. To utilize long-range patterns, we introduce SpecTTTra, a novel architecture that significantly improves time and memory efficiency over conventional CNN and Transformer-based models. In particular, for long audio samples, our top-performing variant outperforms ViT by 8% F1 score while being 38% faster and using 26% less memory. Additionally, in comparison with ConvNeXt, our model achieves 1% gain in F1 score with 20% boost in speed and 67% reduction in memory usage. Other variants of our model family provide even better speed and memory efficiency with competitive performance.
-
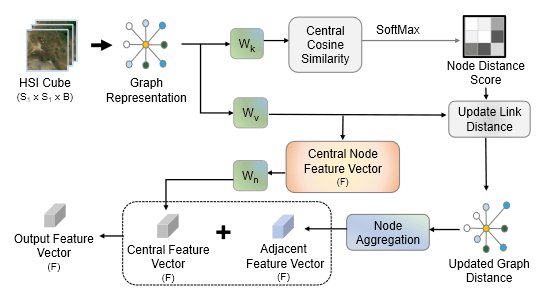 SSGRAM: 3D Spectral-Spatial Feature Network Enhanced by Graph Attention Map for Hyperspectral Image ClassificationBishmoy Paul*, Shaikh Anowarul Fattah, Adnan Rajib, and Mohammad SaquibIEEE Transactions on Geoscience and Remote Sensing, 2025
SSGRAM: 3D Spectral-Spatial Feature Network Enhanced by Graph Attention Map for Hyperspectral Image ClassificationBishmoy Paul*, Shaikh Anowarul Fattah, Adnan Rajib, and Mohammad SaquibIEEE Transactions on Geoscience and Remote Sensing, 2025In this paper, a novel approach to Hyperspectral Image (HSI) classification is proposed using a combination of Convolutional Neural Network (CNN) and Graph Neural Network (GNN) models. A 3D-Spectral Spatial Feature Network (3D-S2FN) is proposed which employs convolutional layers to extract features in spectral, spatial, and spectral-spatial spaces and utilize pyramid squeeze attention to vary the weights among the channels. To complement the existing drawbacks of the CNN-based architectures, a Graph Attention Feature Processor (GAFP) module is introduced that extracts features considering the relative importance of HSI pixels with respect to the pixel that is being classified. A graph attention map (GRAM) is generated by the GAFP module and this map is applied to the 3D-S2FN module intermediate feature to alleviate the inherent neighborhood bias exhibited by CNN-based models. Unlike conventional graph neural networks, the proposed GAFP module processes the data directly, without requiring dimensionality reduction methods that would diminish pixel-level details. The features extracted from the GAFP and enhanced 3D-S2FN are combined to perform the classification task using multiple loss functions. It is shown by extensive experimentation that the proposed SSGRAM method outperforms existing approaches on three publicly available datasets.
2024
-
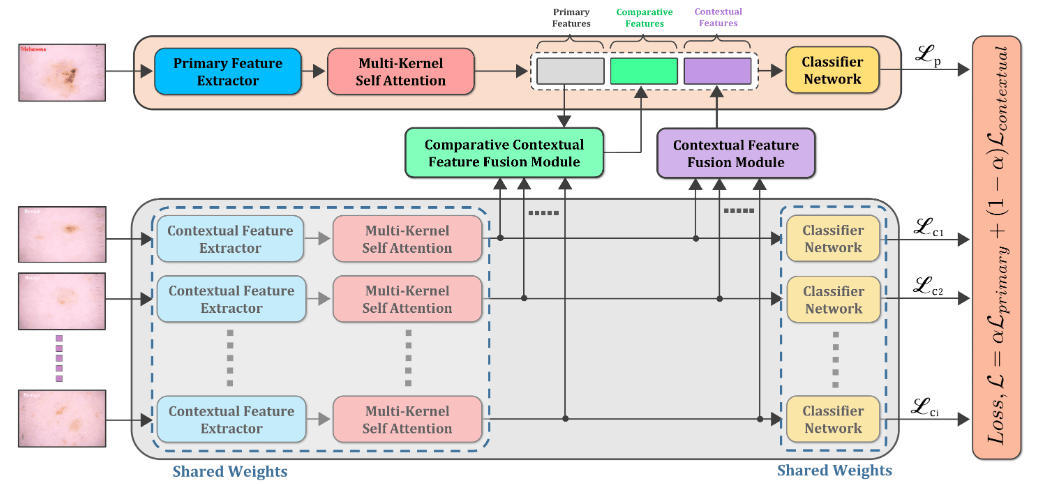 CIFF-Net: Contextual image feature fusion for Melanoma diagnosisMd Awsafur Rahman*, Bishmoy Paul*, Tanvir Mahmud, and Shaikh Anowarul FattahBiomedical Signal Processing and Control, 2024
CIFF-Net: Contextual image feature fusion for Melanoma diagnosisMd Awsafur Rahman*, Bishmoy Paul*, Tanvir Mahmud, and Shaikh Anowarul FattahBiomedical Signal Processing and Control, 2024Melanoma is considered to be the deadliest variant of skin cancer causing around 75% of total skin cancer deaths. To diagnose Melanoma, clinicians assess and compare multiple skin lesions of the same patient concurrently to gather contextual information regarding the patterns, and abnormality of the skin. So far this concurrent multi-image comparative method has not been explored by existing deep learning-based schemes. In this paper, based on contextual image feature fusion (CIFF), a deep neural network (CIFF-Net) is proposed, which integrates patient-level contextual information into the traditional approaches for improved Melanoma diagnosis by concurrent multi-image comparative method. The proposed multi-kernel self attention (MKSA) module offers better generalization of the extracted features by introducing multi-kernel operations in the self attention mechanisms. To utilize both self attention and contextual feature-wise attention, an attention guided module named contextual feature fusion (CFF) is proposed that integrates extracted features from different contextual images into a single feature vector. Finally, in comparative contextual feature fusion (CCFF) module, primary and contextual features are compared concurrently to generate comparative features. Significant improvement in performance has been achieved on the ISIC-2020 dataset over the traditional approaches that validate the effectiveness of the proposed contextual learning scheme.
-
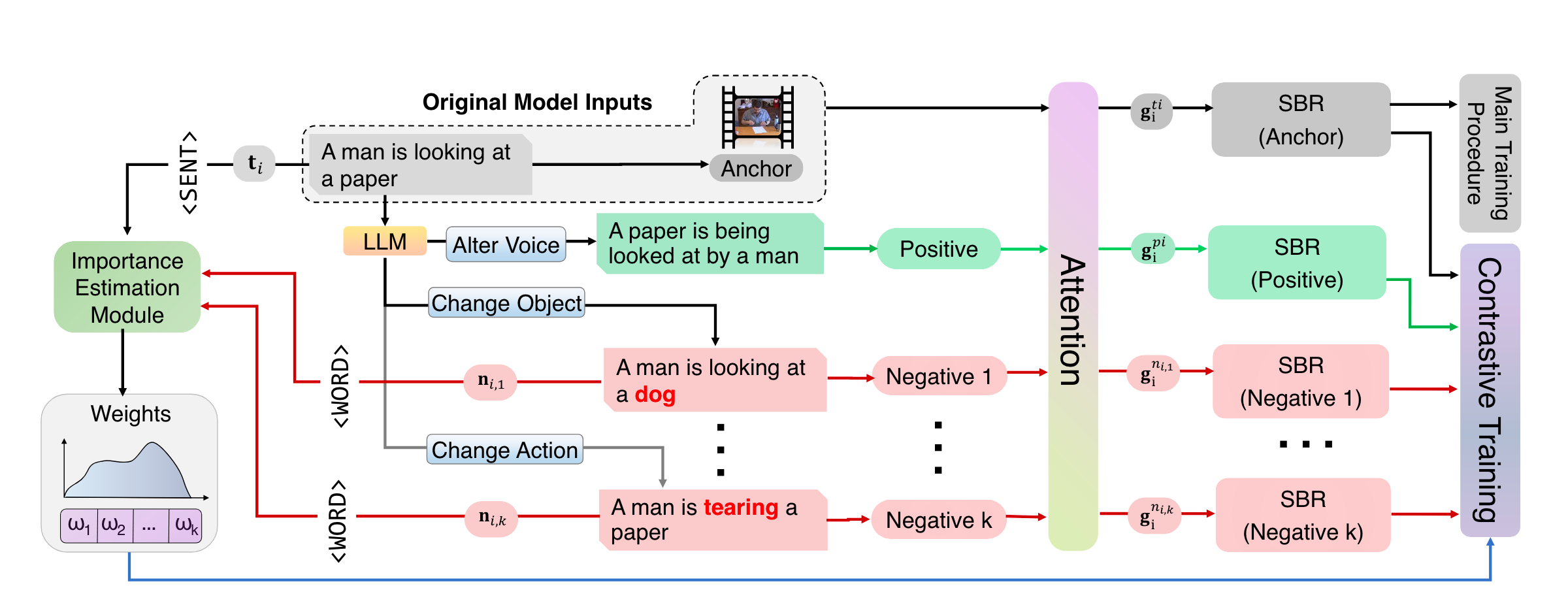 Leveraging Generative Language Models for Weakly Supervised Sentence Component Analysis in Video-Language Joint LearningZaber Ibn Abdul Hakim, Najibul Haque Sarker, Rahul Pratap Singh, Bishmoy Paul, Ali Dabouei, and Min XuProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2024
Leveraging Generative Language Models for Weakly Supervised Sentence Component Analysis in Video-Language Joint LearningZaber Ibn Abdul Hakim, Najibul Haque Sarker, Rahul Pratap Singh, Bishmoy Paul, Ali Dabouei, and Min XuProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2024A thorough comprehension of textual data is a fundamental element in multi-modal video analysis tasks. However, recent works have shown that the current models do not achieve a comprehensive understanding of the textual data during the training for the target downstream tasks. Orthogonal to the previous approaches to this limitation, we postulate that understanding the significance of the sentence components according to the target task can potentially enhance the performance of the models. Hence, we utilize the knowledge of a pre-trained large language model (LLM) to generate text samples from the original ones, targeting specific sentence components. We propose a weakly supervised importance estimation module to compute the relative importance of the components and utilize them to improve different video-language tasks. Through rigorous quantitative analysis, our proposed method exhibits significant improvement across several video-language tasks. In particular, our approach notably enhances video-text retrieval by a relative improvement of 8.3% in video-to-text and 1.4% in text-to-video retrieval over the baselines, in terms of R@1. Additionally, in video moment retrieval, average mAP shows a relative improvement ranging from 2.0% to 13.7 % across different baselines.
2023
-
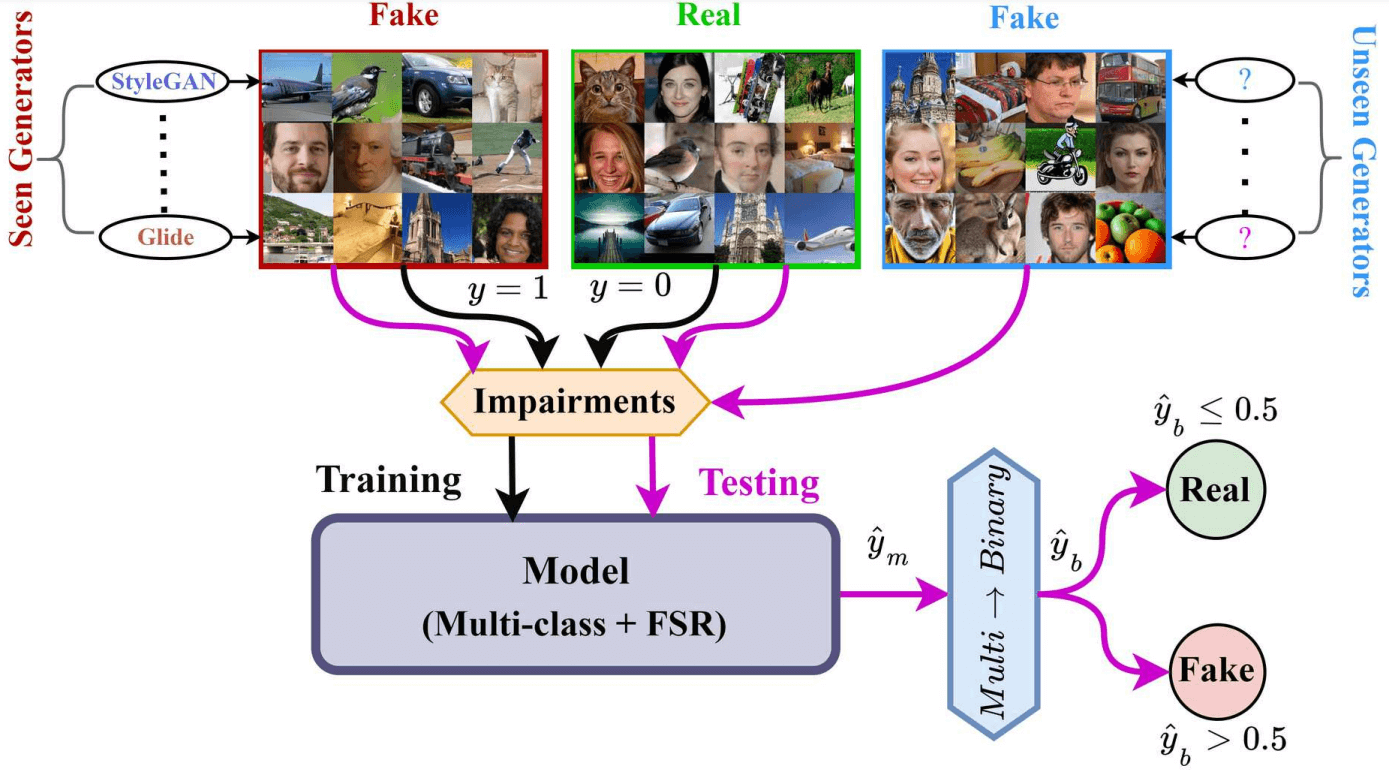 ArtiFact: A Large-Scale Dataset with Artificial and Factual Images for Generalizable and Robust Synthetic Image DetectionMd Awsafur Rahman*, Bishmoy Paul*, Najibul Haque Sarker*, Zaber Ibn Abdul Hakim*, and Shaikh Anowarul FattahIEEE International Conference on Image Processing (ICIP), 2023
ArtiFact: A Large-Scale Dataset with Artificial and Factual Images for Generalizable and Robust Synthetic Image DetectionMd Awsafur Rahman*, Bishmoy Paul*, Najibul Haque Sarker*, Zaber Ibn Abdul Hakim*, and Shaikh Anowarul FattahIEEE International Conference on Image Processing (ICIP), 2023Synthetic image generation has opened up new opportunities but has also created threats in regard to privacy, authenticity, and security. Detecting fake images is of paramount importance to prevent illegal activities, and previous research has shown that generative models leave unique patterns in their synthetic images that can be exploited to detect them. However, the fundamental problem of generalization remains, as even state-of-the-art detectors encounter difficulty when facing generators never seen during training. To assess the generalizability and robustness of synthetic image detectors in the face of real-world impairments, this paper presents a large-scale dataset named ArtiFact, comprising diverse generators, object categories, and real-world challenges. Moreover, the proposed multi-class classification scheme, combined with a filter stride reduction strategy addresses social platform impairments and effectively detects synthetic images from both seen and unseen generators. The proposed solution significantly outperforms other top teams by 8.34% on Test 1, 1.26% on Test 2, and 15.08% on Test 3 in the IEEE VIP Cup challenge at ICIP 2022, as measured by the accuracy metric.
-
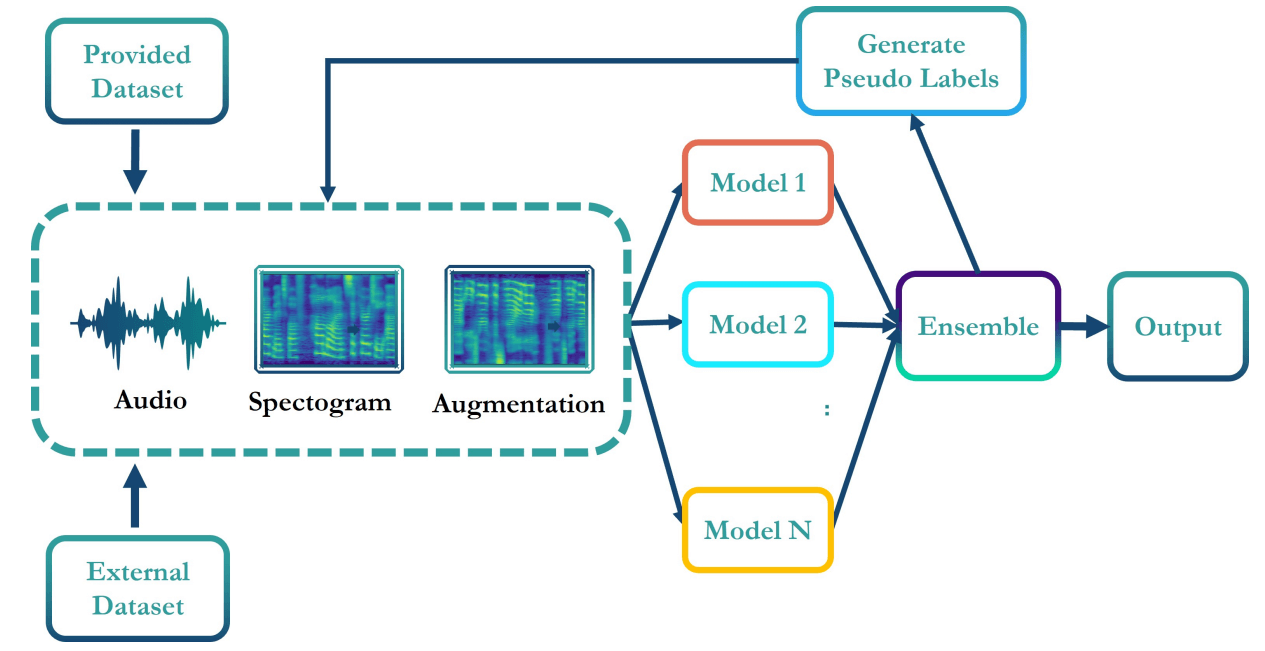 Syn-Att: Synthetic Speech Attribution via Semi-Supervised Unknown Multi-Class Ensemble of CNNsMd Awsafur Rahman*, Bishmoy Paul*, Najibul Haque Sarker*, Zaber Ibn Abdul Hakim*, Shaikh Anowarul Fattah, and Mohammad SaquibPre-print, 2023
Syn-Att: Synthetic Speech Attribution via Semi-Supervised Unknown Multi-Class Ensemble of CNNsMd Awsafur Rahman*, Bishmoy Paul*, Najibul Haque Sarker*, Zaber Ibn Abdul Hakim*, Shaikh Anowarul Fattah, and Mohammad SaquibPre-print, 2023With the huge technological advances introduced by deep learning in audio & speech processing, many novel synthetic speech techniques achieved incredible realistic results. As these methods generate realistic fake human voices, they can be used in malicious acts such as people imitation, fake news, spreading, spoofing, media manipulations, etc. Hence, the ability to detect synthetic or natural speech has become an urgent necessity. Moreover, being able to tell which algorithm has been used to generate a synthetic speech track can be of preeminent importance to track down the culprit. In this paper, a novel strategy is proposed to attribute a synthetic speech track to the generator that is used to synthesize it. The proposed detector transforms the audio into log-mel spectrogram, extracts features using CNN, and classifies it between five known and unknown algorithms, utilizing semi-supervision and ensemble to improve its robustness and generalizability significantly. The proposed detector is validated on two evaluation datasets consisting of a total of 18,000 weakly perturbed (Eval 1) & 10,000 strongly perturbed (Eval 2) synthetic speeches. The proposed method outperforms other top teams in accuracy by 12-13% on Eval 2 and 1-2% on Eval 1, in the IEEE SP Cup challenge at ICASSP 2022.
2021
-
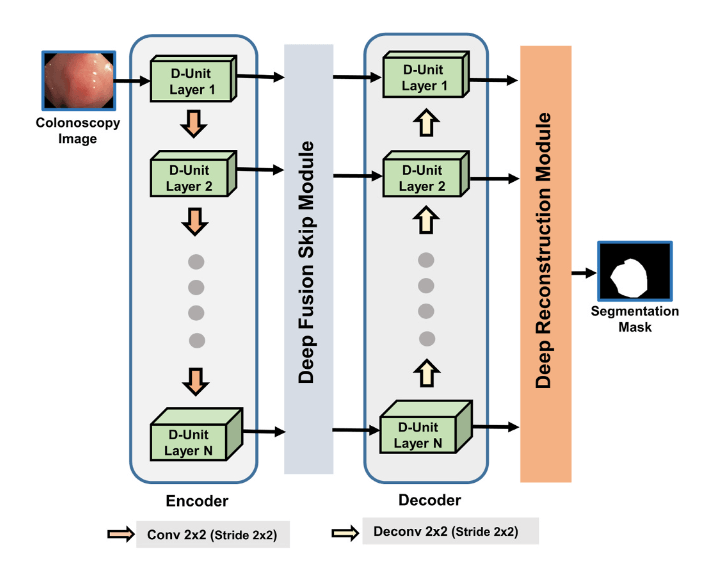 PolypSegNet: A modified encoder-decoder architecture for automated polyp segmentation from colonoscopy imagesTanvir Mahmud, Bishmoy Paul, and Shaikh Anowarul FattahComputers in Biology and Medicine, 2021
PolypSegNet: A modified encoder-decoder architecture for automated polyp segmentation from colonoscopy imagesTanvir Mahmud, Bishmoy Paul, and Shaikh Anowarul FattahComputers in Biology and Medicine, 2021Colorectal cancer has become one of the major causes of death throughout the world. Early detection of Polyp, an early symptom of colorectal cancer, can increase the survival rate to 90%. Segmentation of Polyp regions from colonoscopy images can facilitate the faster diagnosis. Due to varying sizes, shapes, and textures of polyps with subtle visible differences with the background, automated segmentation of polyps still poses a major challenge towards traditional diagnostic methods. Conventional Unet architecture and some of its variants have gained much popularity for its automated segmentation though having several architectural limitations that result in sub-optimal performance. In this paper, an encoder-decoder based modified deep neural network architecture is proposed, named as PolypSegNet, to overcome several limitations of traditional architectures for very precise automated segmentation of polyp regions from colonoscopy images. For achieving more generalized representation at each scale of both the encoder and decoder module, several sequential depth dilated inception (DDI) blocks are integrated into each unit layer for aggregating features from different receptive areas utilizing depthwise dilated convolutions. Different scales of contextual information from all encoder unit layers pass through the proposed deep fusion skip module (DFSM) to generate skip interconnection with each decoder layer rather than separately connecting different levels of encoder and decoder. For more efficient reconstruction in the decoder module, multi-scale decoded feature maps generated at various levels of the decoder are jointly optimized in the proposed deep reconstruction module (DRM) instead of only considering the decoded feature map from final decoder layer. Extensive experimentations on four publicly available databases provide very satisfactory performance with mean five-fold cross-validation dice scores of 91.52% in CVC-ClinicDB database, 92.8% in CVC-ColonDB database, 88.72% in Kvasir-SEG database, and 84.79% in ETIS-Larib database. The proposed network provides very accurate segmented polyp regions that will expedite the diagnosis of polyps even in challenging conditions.